Use-case 2: data are provided by the user
Context
In Ozisik et al., 2021 [1] paper, an overlap analysis is performed between vitamin A and D target genes and processes related to Congenital Anomalies of the Kidney and Urinary Tract (CAKUT).
In this use-case, we illustrate how to use ODAMNet with data provided by user. We use data from Ozisik et al., 2021 [1] paper. Results are compared with those found in the Ozisik et al., 2021 [1] paper.
Vitamin A target genes are coming from Balmer and Blomhoff [2] paper and pathways/processes related to CAKUT are coming from WikiPathways [3], Reactome [4] and Gene Ontology (GO) [5], [6]. Biological networks used are presented in the Networks used page and are coming from the Network Data Exchange (NDEx) [7].
GitHub and GitHub are available in GitHub.
This section presents you how to apply the three different approaches proposed.
Overlap analysis
The Overlap analysis searches intersecting genes between vitamin A target genes and genes involved in pathways/processes related to CAKUT pathways. See Overlap analysis page for more details.
Running Overlap analysis with data provided by user
Target genes file is given using the --targetGenesFile parameter. It contains the list of vitamin A target genes
[FORMAT].
Pathways/processes related to CAKUT are given using the --GMT parameter [FORMAT].
Background genes of each source of pathways/processes is required (--backgroundFile parameter). The file
contains the list of background file names.
Results files are saved into useCases/OutputResults_useCase2/ folder.
odamnet overlap --targetGenesFile useCases/InputData/VitA-Balmer2002-Genes.txt \
--GMT useCases/InputData/PathwaysOfInterest.gmt \
--backgroundFile useCases/InputData/PathwaysOfInterestBackground.txt \
--outputPath useCases/OutputResults_useCase2
Overlap_genesList_withpathOfInterest.csv file is created. It contains results of the overlap analysis between
vitamin A target genes and CAKUT related pathways/processes.
For more details about this output file, see Overlap analysis output files section.
Results of Overlap analysis with data provided by user
Data provided by user overview
Target genes are coming from Balmer and Blomhoff [2]. Pathways of interests are coming from Reactome [4] and WikiPathways [3] and processes of interest are coming from Biological Process (GO) [5], [6]. Data are presented in the Table 13.
Number |
|
|---|---|
Vitamin A target genes |
521 |
Pathways/processes related to CAKUT |
13 |
Pathways/processes sources |
3 |
Overlap analysis results
We performed an Overlap analysis between vitamin A target genes (521) and pathways/processes related to CAKUT (13). We obtained significant overlap between target genes and 7 pathways/processes related to CAKUT (pAdjusted <= 0.05). Results are presented in the Table 14.
PathwayIDs |
PathwayNames |
pAdjusted |
IntersectionSize |
|---|---|---|---|
renal system development |
8.64e-17 |
43 |
|
kidney development |
5.14e-16 |
41 |
|
kidney morphogenesis |
8.33e-12 |
20 |
|
WP:WP5053 |
Development of ureteric collection … |
7.37e-08 |
15 |
WP:WP4823 |
Genes controlling nephrogenesis |
2.88e-04 |
10 |
PMC5748921-PMC6115658 |
CAKUT causal genes |
2.30e-03 |
6 |
WP:WP4830 |
GDNF/RET signalling axis |
1.54e-02 |
5 |
Ozisik et al., [1] identified 7 pathways/processes related to CAKUT disease over 13. ODAMNet found the same 7 pathways/processes.
Active Module Identification (AMI)
The Active Module Identification (AMI) approach identifies active module that contains high number of vitamin A target genes using a protein-protein interaction (PPI) network. AMI is performed using DOMINO [8]. Then, an Overlap analysis is applied between identified active modules and CAKUT pathways/processes. See Active Module Identification page for more details.
Running AMI with data provided by user
Warning
When using DOMINO server, results cannot be identically reproduced. Indeed, DOMINO server doesn’t allow to set the random seed. This random seed changes every new analysis.
Target genes file is given using the --targetGenesFile parameter. It contains the list of vitamin A target genes
[FORMAT].
Pathways/processes related to CAKUT are given using the --GMT parameter [FORMAT].
Background genes of each source of pathways/processes is required (--backgroundFile parameter). The file
contains the list of background file names.
We used a PPI network [SIF file] previously downloaded from NDEx [7]. The PPI network file is provided
using --networkFile parameter (see Network downloading section). Network name should have .sif
extension.
Results files are saved into useCases/OutputResults_useCase2/ folder.
odamnet domino --targetGenesFile useCases/InputData/VitA-Balmer2002-Genes.txt \
--GMT useCases/InputData/PathwaysOfInterest.gmt \
--backgroundFile useCases/InputData/PathwaysOfInterestBackground.txt \
--networkFile useCases/InputData/PPI_HiUnion_LitBM_APID_gene_names_190123.sif \
--outputPath useCases/OutputResults_useCase2
Several files are generated:
DOMINO_inputGeneList_genesList.txt: vitamin A target genes list used for the active module identification.Overlap_AM_*_genesList_withpathOfInterest.csv: results of the Overlap analysis between identified active modules genes and pathways/processes of related to CAKUT. There is one file per active module.DOMINO_genesList_activeModulesNetwork.txt,DOMINO_genesList_overlapAMresults4Cytoscape.txt,DOMINO_genesList_activeModules.txt,DOMINO_genesList_activeModulesMetrics.txtandDOMINO_genesList_signOverlap.txt: some statistics are calculated and saved into files. Theses files are useful for visualisation.
For more details about these files, see AMI output files section.
Results of AMI with data provided by user
Data provided by user overview
Target genes are coming from Balmer and Blomhoff [2]. Pathways of interests are coming from Reactome [4] and WikiPathways [3] and processes of interest are coming from Biological Process (GO) [5], [6]. Data are presented in the Table 15.
Number |
|
|---|---|
Vitamin A target genes |
521 |
Pathways/processes related to CAKUT |
13 |
Pathways/processes sources |
3 |
The PPI network is downloaded from NDEx (see Protein-Protein Interaction (PPI) network). It was build from 3 datasets: Lit-BM, Hi-Union and APID. It contains 15,390 nodes and 131,087 edges.
AMI results
DOMINO defines vitamin A target genes as active genes and searches active modules enriched in active genes. Over the 521 target genes, 468 are found in the PPI and used as active genes by DOMINO. DOMINO identified 21 active modules enriched in vitamin A target genes (Table 16).
Min number |
Max number |
|
|---|---|---|
Edges |
3 |
223 |
Nodes |
4 |
99 |
Target genes |
3 |
19 |
See DOMINO_genesList_activeModulesNetworkMetrics.txt file for more details.
Overlap analysis results
Then, we perform an Overlap analysis between identified active modules (21) and pathways/processes related to CAKUT (13). We obtained significant overlap between 6 identified active modules and 6 pathways/processes (pAdjusted <= 0.05). Results are presented in Table 17.
Pathway IDs |
Pathway Names |
pAdjusted |
|---|---|---|
renal system development |
2.66e-03 |
|
kidney development |
2.66e-03 |
|
kidney morphogenesis |
2.66e-03 |
|
REAC:R-HSA-8853659 |
RET signaling |
5.19e-03 |
WP:WP5053 |
Development of ureteric collection system |
3.21e-02 |
REAC:R-HSA-195721 |
Signaling by WNT |
3.47e-02 |
Duplicates between active modules results are removed and we keep the more significant ones.
The RET signaling and Signaling by WNT reactome pathways were not identified with the overlap approach in the previous study [1] neither with the ODAMNet Overlap analysis.
See DOMINO_genesList_signOverlap.txt file for more details.
Visualisation of AMI results
We created a visualisation of AMI results (Fig. 19) using Cytoscape [9].
We found a significant overlap between 6 active modules and 6 pathways/processes related to CAKUT. For sake of
visualisation, we selected only three of them (Fig. 23). You can find the entire visualisation in the
cytoscape project called AMI_visualisation.cys in GitHub.
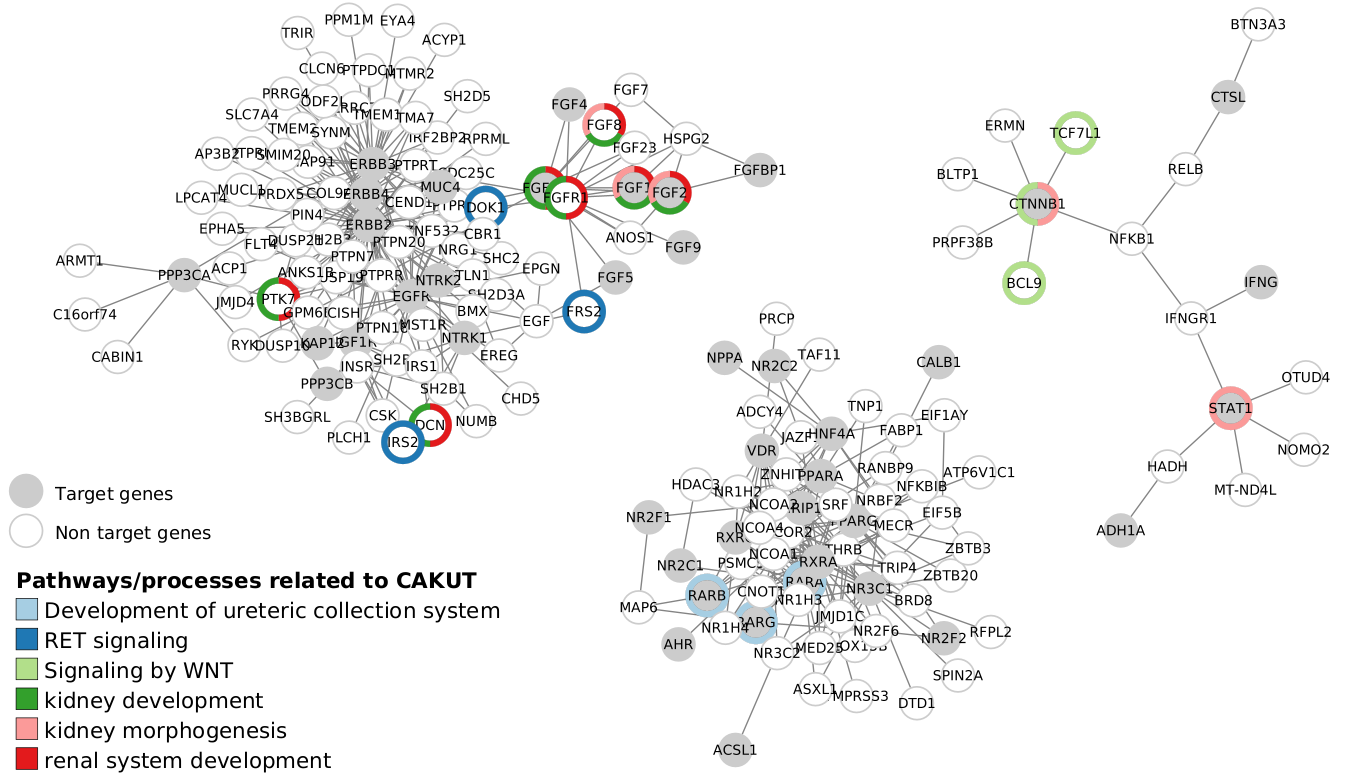
Fig. 23 : Visualisation of 3 active modules and their associated pathways/processes related to CAKUT
Genes are represented by nodes. Grey nodes are target genes, white nodes are non-target genes. Overlap results between active modules and rare disease pathways are displayed using donuts color around nodes. Each color corresponds to a rare disease pathways. Creation steps are explained in the Active module identification results visualisation section.
Module topology is different between modules and associated pathways/processes related to CAKUT also vary (Fig. 23).
The first active module (left in the Fig. 23) is very connected and contains genes involved in several pathways and processes related to CAKUT. Association between vitamin A and RET signaling reactome pathway is indirect. Indeed, genes involved in this pathway are not genes targeted by vitamin A. That explains why we didn’t found this pathways with the Overlap analysis (see Use-case 2 overlap results).
The second active module (middle in the Fig. 23) is also highly connected but its contains genes involved only in one pathways/processes related to CAKUT (Development of ureteric collection system).
The third active module (right in the Fig. 23) is sparser. It contains target genes and non-target genes involved in kidney morphogenesis and Signaling by WNT.
Random Walk with Restart (RWR)
The Random Walk with Restart (RWR) approach mesures proximities between vitamin A target genes and pathways/processes related to CAKUT. To calculate these proximities (RWR scores), we used multiXrank [10] and multilayer networks. See Random Walk with Restart page for more details.
The multilayer network is composed of three gene networks and one pathways/processes related to CAKUT network. Genes nodes are connected to pathways/processes nodes if they are involved in. See Networks used page for more details.
Running RWR with data provided by user
Target genes file is given using --targetGenesFile parameter. It contains list of vitamin A target genes
[FORMAT].
multiXrank needs as input a configuration file (--configPath) that contains path of networks and analysis
parameters. We used multiXrank with default parameters.
We provide a name file to save vitamin A target genes (i.e. seeds) --seedsFile useCases/InputData/seeds.txt and
also a SIF file name (--sifFileName) to save the top nodes based on RWR score (--top 20).
Results files are saved into useCases/OutputResults_useCase2/ folder.
odamnet multixrank --targetGenesFile useCases/InputData/VitA-Balmer2002-Genes.txt \
--configPath useCases/InputData/config_minimal_useCase2.yml \
--networksPath useCases/InputData/ \
--seedsFile useCases/InputData/seeds.txt \
--sifFileName UseCase2_RWR_network.sif \
--top 5 \
--outputPath useCases/OutputResults_useCase2
Tip
Several files are generated into RWR_genesList/ folder:
config_minimal_useCase2.ymlandseeds.txt: copies of the input filesmultiplex_1.tsvandmultiplex_2.tsv: RWR scores for each multilayer. 1 is the genes multilayer network RWR scores and 2 is the pathways/processes related to CAKUT network RWR scores.UseCase2_RWR_network.sif: SIF file name that contains the network resultRWR_topX.txt: Top X of pathways/processes related to CAKUT
For more details about these files, see RWR output files section.
Results of RWR with data provided by user
Data provided by user overview
Target genes are coming from Balmer and Blomhoff [2]. There are 521 vitamin A target genes.
RWR results
Analysis with pathways/processes related to CAKUT network
We used a multilayer network composed of three gene networks and one pathways/processes related to CAKUT network (Fig. 18 - left, Genes multilayer network and Rare disease pathways network).
multiXrank defines vitamin A target genes as seeds. Over the 521 target genes, 480 are found in the multilayer and used as seeds. Using the RWR scores (i.e. proximity score with the target genes), pathways/processes related to CAKUT are prioritized. We selected the top 5 (Table 18).
Nodes (pathway IDs) |
Pathway Names |
RWR scores |
|---|---|---|
renal system development |
2.12e-03 |
|
kidney development |
1.86e-03 |
|
REAC:R-HSA-195721 |
Signaling by WNT |
1.69e-03 |
REAC:R-HSA-157118 |
Signaling by NOTCH |
1.19e-03 |
WP:WP5053 |
Development of ureteric collection system |
6.46e-04 |
We created a visualisation of the results (Fig. 24) using Cytoscape [9]. You can retrieved
it in the cytoscape project called RWR_visualisation.cys in GitHub. The Fig. 24
presents the top 5 of pathways/processes related to CAKUT, ordered by RWR score.

Fig. 24 : Top 5 of the pathways/processes related to CAKUT prioritized using RWR score using a (disconnected) pathways/processes related to CAKUT network
Pathways/processes related to CAKUT are in pink triangles. Target genes are in grey and non-target genes are in white. Creation steps are explained in the Random walk with restart results visualisation section.
Extra : analysis with disease-disease similarity network
Tip
Same command line, but needs to change configuration file.
We also propose to run an RWR approach using a disease-disease similarity network. In this network, rare diseases are linked together according their phenotype similarity whereas in the previous network they were not at all connected.
We used a multilayer network composed of three genes network and one disease-disease similarity network (Fig. 18 - right, Genes multilayer network, Disease-disease similarity network).
multiXrank defines vitamin A target genes as seeds. Over the 521 target genes retrieved from CTD, 480 are found in the multilayer and used as seeds. Using the RWR scores (i.e. proximity score with the target genes), rare disease are prioritized. We selected the top 20 and presented the top 5 (Table 19).
Nodes (disease IDs) |
Disease Names |
RWR scores |
|---|---|---|
OMIM:178500 |
Pulmonary fibrosis, idiopathic |
3.47e-04 |
OMIM:125853 |
Diabetes mellitus, noninsulin-dependent |
3.13e-04 |
OMIM:215600 |
Cirrhosis, familial |
2.73e-04 |
OMIM:613659 |
Gastric cancer, somatic |
2.38e-04 |
OMIM:104300 |
Alzheimer disease |
2.34e-04 |
We created a visualisation of the results (Fig. 25) using Cytoscape [9]. You can retrieved it in
the cytoscape project called RWR_visualisation.cys in GitHub. The Fig. 25 presents the
top 5 of rare disease pathways, ordered by RWR score.

Fig. 25 : Top 5 of the rare disease prioritized using RWR score using disease-disease similarity network
Rare disease are in pink triangles. Target genes are in grey and non-target genes are in white. Creation steps are explained in the Random walk with restart results visualisation section.
Overlap, AMI and RWR results comparison
We compare results obtained with the three different approaches: Overlap analysis, Active Module Identification (AMI) and Random Walk with Restart (RWR). We used orsum [11], a Python package to filter and integrate enrichment analysis from several analyses. The main result is a heatmap, presented in Fig. 26.
orsum.py --gmt 00_Data/hsapiens_background.gmt \
--files 00_Data/Overlap.4Orsum 00_Data/DOMINO.4Orsum 00_Data/RWR_top5.4Orsum \
--fileAliases Overlap AMI RWR \
--maxRepSize 0 \
--outputFolder UseCase2_orsum
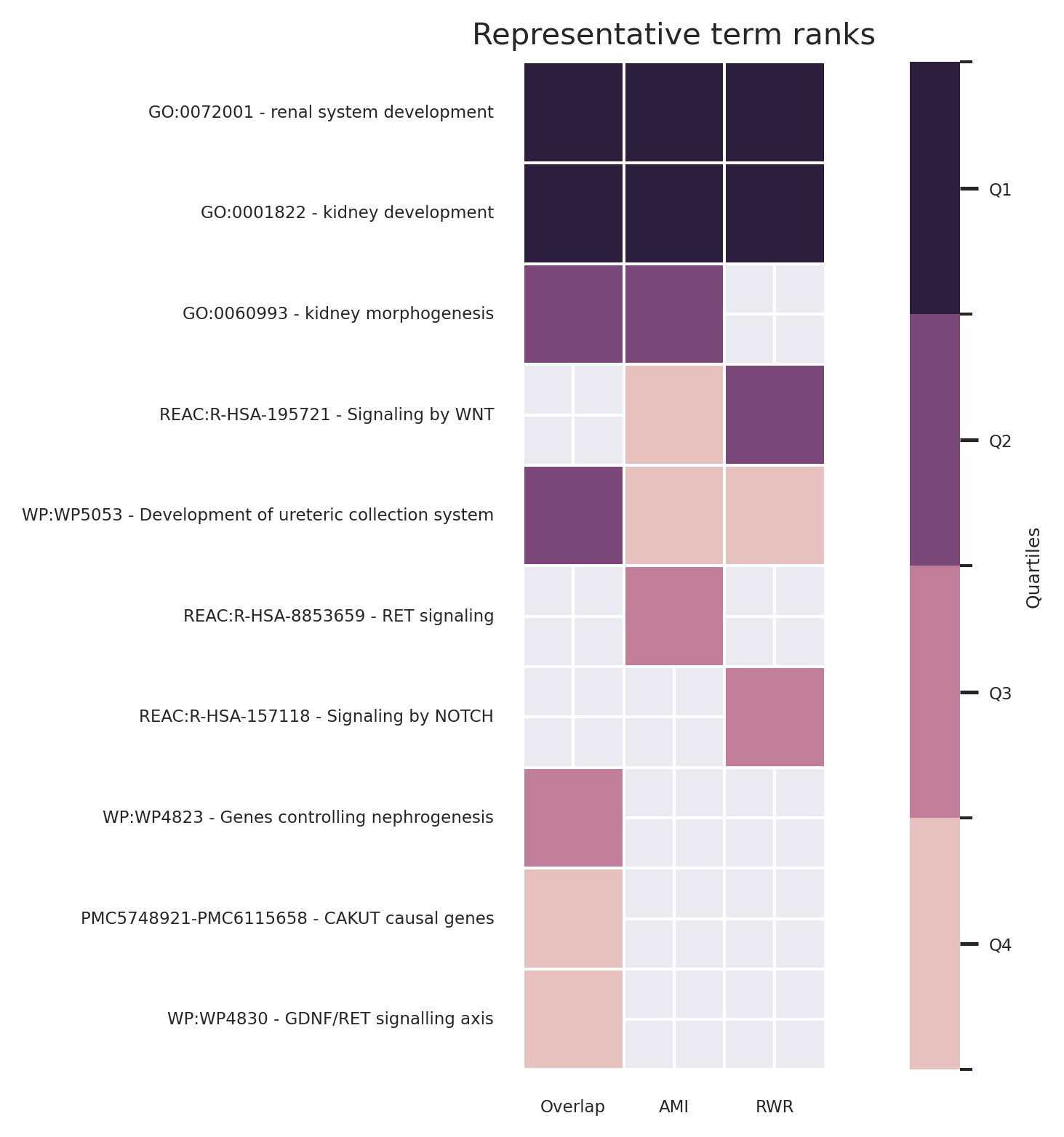
Fig. 26 : Overlap analysis (Overlap), Active module identification (AMI) and Random walk with restart (RWR) results integration and comparison using orsum
The --maxRepSize parameter is set to 0 to consider each term as is own representative term.
Some pathways/processes related to CAKUT are retrieved associated with vitamin A by all the three approaches such as renal system development and kidney development. Some other are retrieved associated with vitamin A only by one (RET signaling) or two (Signaling by WNT) approaches.