Networks used
Warning
Gene IDs have to be consistent between input data (target genes, GMT and networks)
When data are retrieved by queries, HGNC IDs are used.
In this section, we present networks used in the use-cases.
We propose to apply the random walk with restart (RWR) approach on two different multilayers.
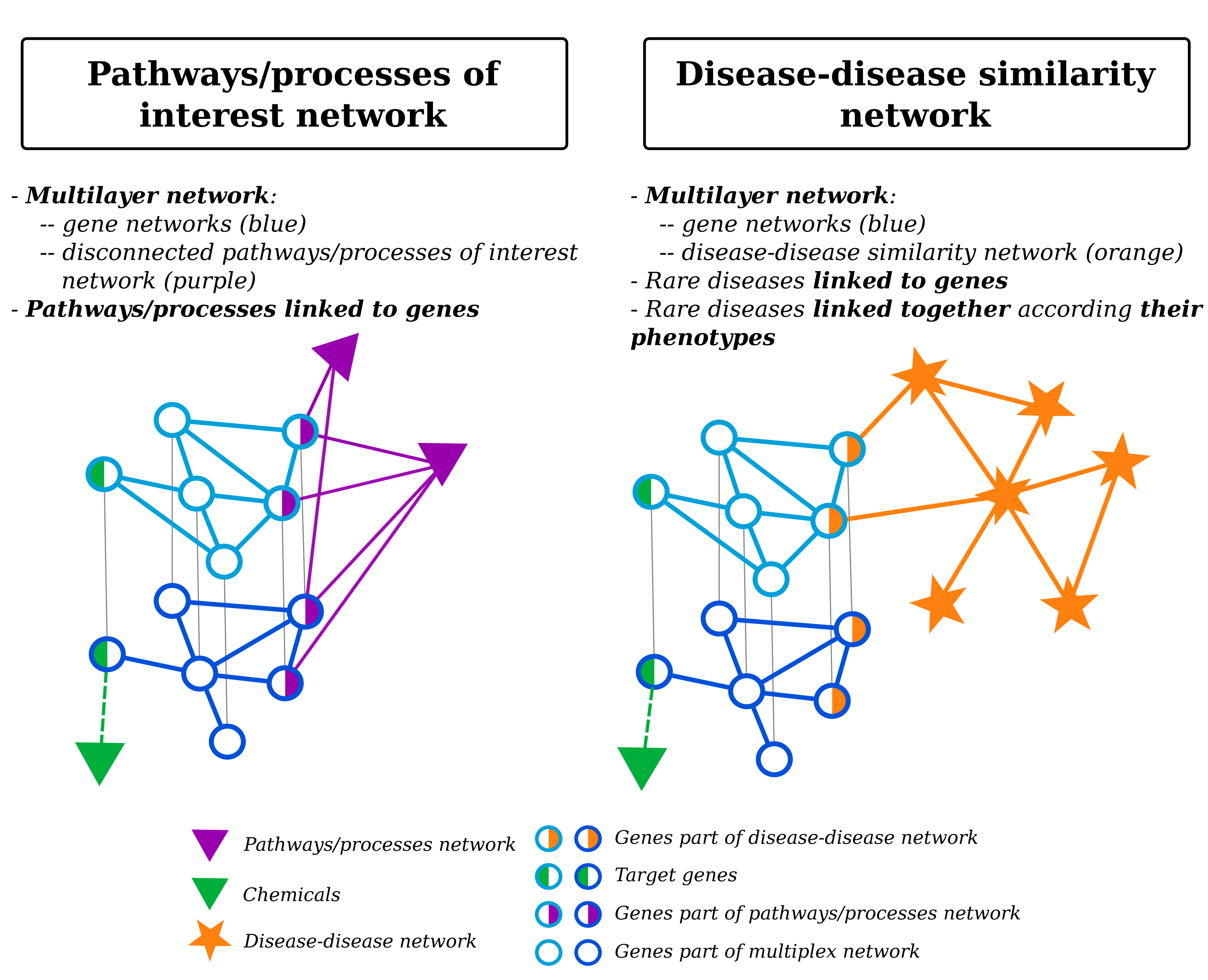
Fig. 18 : Multilayers composition: On the left, multilayer is composed of genes multilayer network and pathways/processes of interest network (disconnected network). On the right, the multilayer is composed of genes multiplayer network and disease-disease similarity network.
Multilayers are composed of:
genes multilayer network + pathways/processes of interest network (Fig. 18 - left part)
genes multilayer network + disease-disease similarity network (Fig. 18 - right part)
Genes multilayer network
The genes multilayer network is composed of three different networks. Nodes are identical between networks, but the relationships between them are coming from different sources. Networks are downloaded from the Network Data Exchange (NDEx) [1] (see Network downloading page).
Protein-Protein Interaction (PPI) network
The Protein-Protein Interaction (PPI) network is obtained from fusion of three datasets : Hi-Union and Lit-BM [2] and APID [3]. It’s composed of:
15,390 nodes
131,087 edges
This network is also used for the active module identification approach.
Molecular complexes network
Molecular complexes network is constructed from the fusion of Hu.map [4] and Corum [5]. It’s composed of:
8,497 nodes
62,073 edges
Reactome pathways network
The Reactome pathways network was build using data derived from Reactome protein-protein interaction data [6]. It’s composed of:
4,598 nodes
19,292 edges
Use-case command lines
odamnet networkDownloading --netUUID bfac0486-cefe-11ed-a79c-005056ae23aa \
--networkFile useCases/InputData/multiplex/1/PPI_HiUnion_LitBM_APID_gene_names_190123.gr \
--simple True
odamnet networkDownloading --netUUID 419ae651-cf05-11ed-a79c-005056ae23aa \
--networkFile useCases/InputData/multiplex/1/Complexes_gene_names_190123.gr \
--simple True
odamnet networkDownloading --netUUID b13e9620-cefd-11ed-a79c-005056ae23aa \
--networkFile useCases/InputData/multiplex/1/Pathways_reactome_gene_names_190123.gr \
--simple True
Pathways/processes of interest network
In the use-case 1, we are using data retrieved from databases. So, we created a rare disease pathways network with data retrieved from WikiPathways [7]. The network is composed of 104 nodes and the bipartite contains 4,612 interactions between genes and rare disease pathways.
In the use-case 2, we are provided data from a previous study [8]. We created a disconnected network with pathways and processes related to Congenital Anomalies of the Kidney and Urinary Tract (CAKUT) as nodes. The network is composed of 13 nodes and the bipartite network contains 1,655 interactions between genes and pathways and processes related to CAKUT.
To know how to create these two networks, see the Network creation page.
Disease-disease similarity network
Disease-disease similarity network creation
We constructed a disease-disease network based on the phenotype similarity between diseases. A disease is defined as a set of phenotypes and each phenotype is associated to the Human Ontology Project IDs (HPO) [9].
The similarity score is calculated based on the number of shared phenotypes between two diseases ([10], [11], [12]). Every pairs of diseases have a similarity score. To create the network, we selected the 5 most similar diseases fo each disease.
The disease-disease similarity network contains 33,925 edges and 8,264 diseases.
Gene-disease bipartite
The molecular multilayer network is connected to the disease-disease similarity network with the gene-disease bipartite. The bipartite contains 6,564 associations (4,483 genes and 5,878 diseases).